-
Debugging flaky browser specs in a Github Action (Flaky Specs part 5)
The most “fun” flaky spec to debug is a flaky browser spec that only fails intermittently in CI. What now?
To debug these effectively:
- Force your Github Action container to stay alive
- Provide a way to SSH in
- Provide a way to see the actual browser and interact with it
Capybara running over VNC in the Github Action container:
The above was setup using my “ci_vnc” scripts that are designed to setup SSH+VNC on a Github Action on EC2. I’m hoping to iterate on them and turn them into a reusable Github Actions Marketplace action.
That is the most secure method as it does not rely on any 3rd party service proxies like
uptermorngrok.If you are OK with relying on such services, there is a more drop-in github action approach that relies on
ngrok. -
Debugging flaky specs in a Github Action (Flaky Specs, Part 4)
Run your spec directly in CI / Github Action
If you are unable to reproduce the error locally - try running your spec directly in CI. Github Actions and CI in general aren’t designed to allow you to SSH into them, but you can still do that with a couple of changes:
Upterm Github Action
The Upterm Github Action does both of these things for you:
- name: Setup upterm session uses: lhotari/action-upterm@v1 if: failure() with: wait-timeout-minutes: 30If your specs fail, this sets up upterm + tmux and provides an SSH connection string and force the container to stay alive for 30 minutes. To connect, watch your the build log untill you see:
=== F8S2LCNHYCL8S3WGMW72 Command: tmux new -s upterm -x 132 -y 43 Force Command: tmux attach -t upterm Host: ssh://uptermd.upterm.dev:22 SSH Session: ssh F8S2LCn..........<REDACTED>...............FsOjIyMjI=@uptermd.upterm.devThen you can connect by copying the
sshconnection string, and run your tests directly on the Github Action container: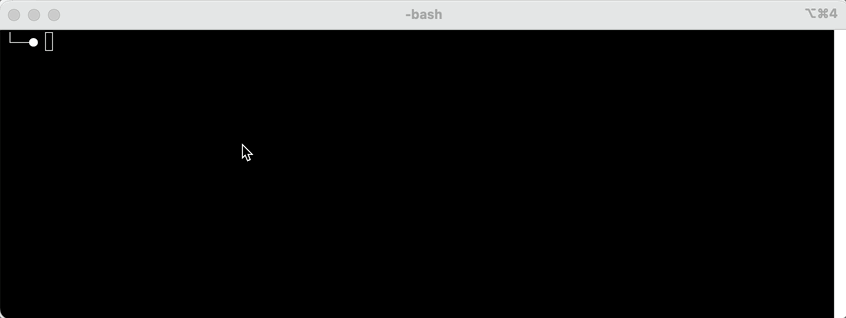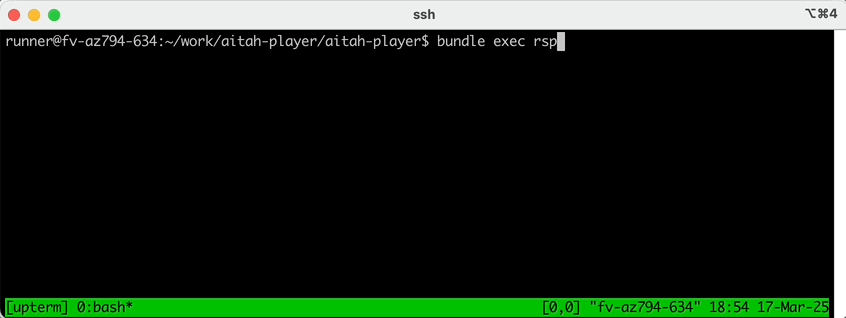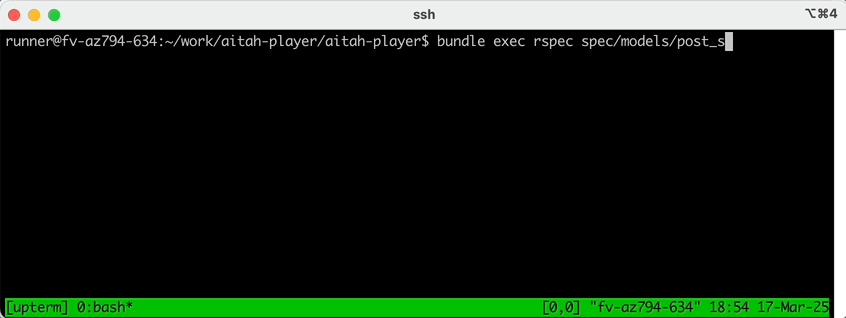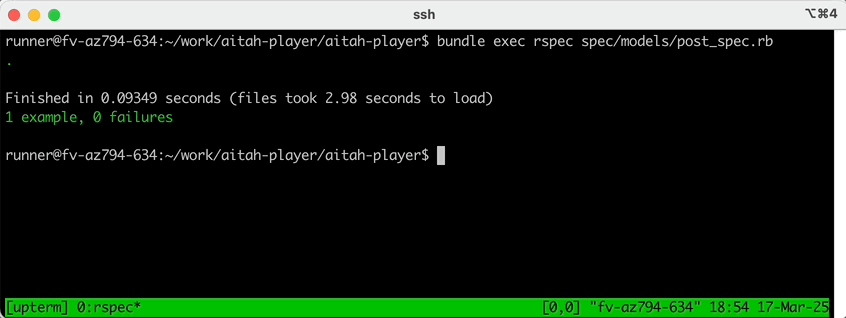
- For upterm, you can run your own uptermd
- Configure Github Actions to run on your own containers (via AWS/EC2 or similar), then connect directly
-
Flaky specs (part 3)
Sometimes specs only fail on CI, and pass locally. The first thing to try is running the test suite locally in the same order locally:
Look for
Randomized with seed 14427in your CI test run output. Grab the seed and then run the test suite locally with it:bundle exec rspec --seed 14427 -
How to deal with flaky rspec tests (flaky specs, part 2)
Leaving flaky specs in your tets suite may seem not very harmfull. It just requires developers to sometimes rerun the test suite, so what?
The thing is - besides just reducing overall developer productivity, you are also training yourself to ignore or not rely on the tests as much. This can be much more harmful.
Instead of letting flaky specs fester, take the following two steps immediately:
- Mark all your flaky specs with a tag:
describe "it works", :flaky do end- Change your CI to skip the flaky specs by using the
--tag ~flakyrspec option. In a Github Action that might look like this:
- name: Run tests id: rspec continue-on-error: true run: bundle exec rspec --tag ~flaky --format documentation --colorThis immediately stops the bleeding. Now the team can work through all the flaky specs one at a time to attempt to fix them.
Bonus: This allows you to run JUST the flaky specs in an attempt to reproduce the flakiness (more on that soon):
bundle exec rspec --tag flaky(
~excludes flaky specs, no~limits it to only flaky specs) -
Debugging flaky specs - part 1
Everyone’s favorite topic: flaky specs.
There is no one solution because it’s not one problem. But for the most part a flaky spec’s root cause will always come down to something introducing non-determinism.
List of some common non-deterministic root causes:
- Specs can be run in a random order (which is a good thing). When one test leaks state, this can result in subsequent tests failing intermittently.
- Browser tests (for example, using Capybara) can be notoriuos for flakiness. When using an actual running browser - we’re dealing with multiple processes and threads even if our code does not use concurrency. Even just the complexity of the browser itself results in non-deterministic response times.
- SQL queries without an
order byclause by definition do not guarantee order. The resulting data set will be in a random order and if a test relies on the order for it’s assertion, that will fail intermittently. - Anything else that can introduce randomness and nondeterminism can result in flakiness.
A good simple first step when attempting to troubleshoot a flaky spec is to see if it’s flaky in isolation:
for _ in $(seq 1 to 100); do bundle exec rspec spec/system/login_spec.rb || break; endThe above runs the spec 100 times until it fails, and then stops.
-
How to not re-record VCR cassettes, part 3
Custom Matchers allow a lot of flexibility. For example for an app that deals with Reddit URLs, this matcher allows any variation of the reddit URL to match as long as the Post ID matches:
module VCRHelpers reddit_url= ->(request_1, request_2) { extract_reddit_id(request_1) == extract_reddit_id(request_2) } end(Bonus: Uses the neat Ruby lambda syntax)
Then to use it:
describe 'my test', vcr: { match_requests_on: [ VCRHelpers::reddit_url ] } do } -
How to not re-record VCR cassettes part 2
More ways to not re-record VCR cassettes when you test changes:
- Surgically modify the cassette YAML file to match the changes. Not ideal but works in a pinch.
- When the test includes a series of HTTP requests and only one changed: manually remove that one
request:key from the cassette YAML file, change your cassette options torecord: :new_episodesand re-run the test. It will only re-record the one you deleted. - If the problem stems from the sequence of HTTP requests changing, or from HTTP requests getting called multiple times try
allow_playback_repeats: true. allow_unused_http_interactionsdefaults totruebut in case its set tofalsein your test, changing it back totruemight save you.
 I help out with the VCR gem, but it can always use more maintainers.
I help out with the VCR gem, but it can always use more maintainers.
If you'd like to help maintain a well-used gem please spend some time reviewing pull requests, issues, or participating in discussions. We're also always grateful for .
.
-
How to not re-record VCR cassettes (part 1)
Sometimes when you make some small changes to a test that uses VCR the existing VCR recording varies just enough so that VCR insists that you re-record the VCR cassette, with the dreaded “VCR does not not know how to handle” error message. If rerecording the cassette requires a lot of setup, it’s useful to have a few workarounds to avoid this.
This will be a series of posts, and I’m going to start with the obvious ones.
The most straightforward way approach is to modify the
match_requests_oncassette option. By default VCR matches on:methodand:uri. Customize this with:describe "my test", vcr: { record: :none, match_requests_on: [:method, :path] } do endThe example above changes
:urito:path, which could be a valid thing to do if the hostname changed a bit but the path did not. As long as you determine that the test is still valid (and valuable) without being strict about the hostname this change will prevent the need to re-record. THe possible values are::body,:uri,:headers,:host,:method,:path,:query,:uri,:body_as_json.Stay tuned for follow up posts with more involved approaches, custom matchers, hacks and workarounds!
I help out with the VCR gem, but it can always use more maintainers.
If you'd like to help maintain a well-used gem please spend some time reviewing pull requests, issues, or participating in discussions. We're also always grateful for.
-
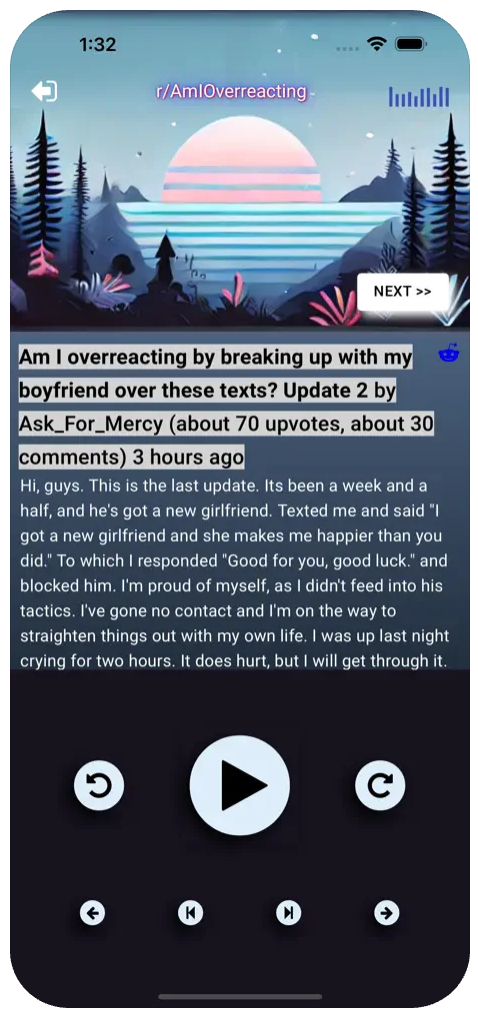
AITAH Player
I did a thing!
My wife, son & I like listening to posts from subreddits like r/amitheasshole and r/amiwwrong while we’re in the car, and then discussing and rendering our own judgement. However, the text-to-speech on the reddit app is pretty bad, so I built an app that does it better.
It works kind of like a Spotify for reddit advice posts - it reads out the post and the top comments.
-
Capybara click_on_text
Capybara is great. But it’s also kind of “idealistic” in that it only wants to interact with the page in a way that conforms to perfectly formed semantic HTML. This does not always conform with the reality. Ideally this motivates improvements to the site structure, but in the meantime there is
click_on_text. Capybara can assert based on text on the page, and it can click on buttons and links. But there is no way to click on any text on the page without resorting to the lower level helpers such asfind,alland working directly with theCapybara::Nodeobjects.Usage:
click_on_text 'More details'It uses xpath to find the text on the page and click on it.
Include it in
spec/rails_helper.rb:require Rails.root.join('spec/support/click_on_text.rb') RSpec.configure do |config| config.include ClickOnText, type: :system endAnd drop this in
spec/support/click_on_text.rb:module ClickOnText def click_on_text(text) element = find_by_text(text) element.click end def find_by_text(text) xpath = ".//*[text()=#{escape_for_xpath(text)}]" find(:xpath, xpath) end # Yes, this is necessary. Xpath doesn't support escaping both single quotes and double # quotes in the same string so requires using `concat`. def escape_for_xpath(text) if text.include?("'") && text.include?('"') parts = text.split("'") concat_parts = parts.map { |part| "'#{part}'" }.join(", \"'\", ") "concat(#{concat_parts})" elsif text.include?("'") "\"#{text}\"" else "'#{text}'" end end end -
git find
If you’re like me you might have tens (or hundreds?) of “draft branches” from various spikes, experiments and aborted attempts at features.
git findsearches through your local branches to find a branch that has the code you’re looking for in it’s diff. Usage:$ git find Search through all local branches for a string in the diff. Usage: git-find <string> git-find <string> <base_branch> $ git find vnc base branch: master DAT-20177_debug_flaky_specs DAT-20177_flaky_draftsTo set this up, place this script somewhere in your path. Git will automatically translate
git findtogit-find:git-find:#! /bin/bash # set the default base branch DEFAULT_BASE_BRANCH="master" if [ -z "$1" ]; then echo -e "\nSearch through all local branches for a string in the diff. Usage:\n" echo -e "git-find [string]" echo -e "git-find [string] [base_branch]\n" exit 1 fi base_branch="${2:-$DEFAULT_BASE_BRANCH}" # Check if the base branch exists if ! git show-ref --verify --quiet "refs/heads/$base_branch"; then echo "Base branch '$base_branch' does not exist." exit 1 fi echo "base branch: $base_branch" for branch in $(git branch --format='%(refname:short)'); do diff_output=$(git diff "$(git merge-base "$branch" "$base_branch")" "$branch" | grep "$1") if [ -n "$diff_output" ]; then echo "$branch" fi done -
git last
cd -andgit checkout -both switch back to the previous folder and branch you were on, respectively.I use this frequently but it doesn’t work so well with
gitbecause more often than not I switched tomainin between the two branches.git lastwas made to solve this:git lastDisplays the last 10 branches you were on, and allows you to switch to one of them. Usage:
$ git last 1 aitah_judgement_bot 2 comment_posting_class 3 fix_codespaces 4 fix_reddit_authed_requests 5 schedule 6 display_number_of_post_sentences 7 separate_daily_jobs_into_3_schedules 8 new_devcontainer 9 fix_logs_controller_cant_find_track_event 10 fix_logs_controller_error Enter the number of the branch you want to checkout (or press Enter to skip): 3 Switched to branch 'fix_codespaces' [~/workspace/aitah-player]─[±] fix_codespaces {29} ✓Below is the script. Place it anywhere in your path, and
gitwill be smart enough to translategit lasttogit-last:git-last:#!/bin/bash # Get the current branch name current_branch=$(git rev-parse --abbrev-ref HEAD) # Generate the list of branches excluding the current one and non-existent branches branches=$(git reflog --date=iso | grep checkout | awk '/checkout: moving from/ {print $8}' | grep -v '^[0-9a-f]\{40\}$' | grep -v "$current_branch" | awk '!seen[$0]++' | while read branch; do if git show-ref --verify --quiet refs/heads/$branch; then echo $branch fi done | head -n 10) # Print the branches with line numbers echo "$branches" | nl -n ln # Ask the user to select a branch read -p "Enter the number of the branch you want to checkout (or press Enter to skip): " branch_number # Check if branch_number is not empty if [ -n "$branch_number" ]; then # Get the name of the selected branch branch_name=$(echo "$branches" | sed "${branch_number}q;d") # Check if the branch name is not empty if [ -n "$branch_name" ]; then # Checkout the selected branch git checkout "$branch_name" else echo "Invalid branch number. Skipping checkout." fi else echo "No branch number entered. Skipping checkout." fi -
prep_prompt.sh
While Github Copilot and Cline are integrated into the IDE and are excellent, sometimes I want a 3rd or 4th opinion.
My
prep_prompt.shprepares my code for pasting into the prompt. It doesn’t do much but it’s very helpful:- It adds the name of the file before each file
- It adds code fence blocks (```) before and after the code
- It concatenates all the source files passed into it
- It copies it to the (macos) clipboard
Usage:
- Basic usage:
$ prep_prompt README.md app/controllers/application_controller.rb Copied into clipboard.- The larger context sizes all the LLMs have been rolling out have been game changers, and this make sharing your entire app possible:
$ prep_prompt $(find * | grep rb$) Copied into clipboard.Now you can ask questions that require broader visibility of your entire app, instead of about individual files or snippets.
- The
--verboseoption shows what is being copied:
$ prep_prompt README.md app/controllers/application_controller.rb --verbose Included files: * README.md * app/controllers/application_controller.rb `README.md`: ``` # README This README would normally document whatever steps are necessary to get the application up and running. ``` `app/controllers/application_controller.rb`: ``` class ApplicationController < ActionController::Base # Only allow modern browsers supporting webp images, web push, badges, import maps, CSS nesting, and CSS :has. allow_browser versions: :modern end ``` Copied into clipboard.To use, place this script anywhere in your path:
Read more
subscribe via RSS
Progress on the "secret door"!.






















